hive使用bulkLoad批量导入数据到hbase
本文主要参考了hbase和hive官方文档的说明,并结合cdh和hdp的一些教程以及个人在生产中的实践进行记录。主要内容有hbase bulkload的原理以及对应hive的操作步骤,最后基于cdh进行完整实验提供参考实例。
不过整个操作确实很复杂繁琐,不是很建议使用。现在有挺多使用Spark Bulkload,下次有机会尝试一下。
之前是遇到一个需求,源表在hbase上,需要重新生成rowkey并提取部分字段形成新表。功能很简单,就是行对行映射过去,但是效率太低耗时太长,用bulkload确实解决了当时的麻烦。
写这篇文章是对自己操作的复盘,同时也梳理一下知识。
实验环境为:CDH6.3.2,对应的各个组件版本为:hadoop3.0.0,hbase2.1.0,hive2.1.1
一 hbase bulk loading批量加载 原理
这里推荐阅读hbase 最新官方文档:http://hbase.apache.org/2.3/book.html#arch.bulk.load
注意官方文档提供了2.2版本和2.3版本,这里原理讲解使用的是最新的,具体操作需结合根据实际使用版本来,有一些细节可能存在差异,例如2.2和2.3版本最终bulkload使用的jar包名称不一样。
这里简单地机翻一下:
1 概述
HBase包括几种将数据加载到表中的方法。 最直接的方法是使用MapReduce任务中的TableOutputFormat类,或使用常规客户端API。 但是,这些方法并不总是最有效的方法。
批量加载功能使用MapReduce任务以HBase的内部数据格式输出表数据,然后将生成的StoreFiles直接加载到正在运行的集群中。 与通过HBase API进行加载相比,使用批量加载将占用更少的CPU和网络资源。
2 批量加载架构
HBase批量加载过程包括两个主要步骤。
1. 通过MapReduce作业准备数据
批量加载的第一步是使用HFileOutputFormat2从MapReduce任务生成HBase数据文件(存储文件)。这种输出格式以HBase的内部存储格式写出数据,以便稍后可以有效地将它们加载到集群中。
为了有效地运行,必须配置HFileOutputFormat2,使每个输出的HFile都适用于单个region。为此,那些 输出结果将被批量加载到HBase中 的MapReduce任务,使用 Hadoop 的 TotalOrderPartitioner 类将map输出划分为 key 空间的不相交范围,该范围与表中 region 的 key 范围相对应。
HFileOutputFormat2包括一个便捷函数configureIncrementalLoad(),该函数根据表的当前区域边界自动设置TotalOrderPartitioner。
2. 完成数据加载
在准备好要导入的数据之后,通过使用具有 “importtsv.bulk.output” 选项的 importtsv 工具,或通过使用 HFileOutputFormat 的 MapReduce 作业,可以使用 completebulkload 工具将数据导入到正在运行的集群中。 此命令行工具遍历准备好的数据文件,并为每个文件确定文件所属的region。 然后,它将连接上 HFile 对应的合适的 RegionServer ,将其移入其存储目录并将数据提供给客户端。
如果region边界在批量加载准备过程中或在准备和完成步骤之间发生了更改,则completebulkload程序将自动将数据文件分割为与新边界对应的部分。这个过程效率不高,所以用户应该尽量减少准备批量加载和将其导入集群之间的延迟,特别是当其他客户机通过其他方式同时加载数据时。
1 | |
如果类路径中没有提供相应的hbase参数,那么-c config-file选项可以用来指定包含相应hbase参数的文件(例如hbase-site.xml)(另外,如果zookeeper不是由hbase管理的,那么类路径必须包含包含zookeeper配置文件的目录)。
二 hive 操作步骤
这里主要参考hive的文档:https://cwiki.apache.org/confluence/display/Hive/HBaseBulkLoad
1. 确定目标hbase表的结构
这里需要明确最终导入的hbase表的几个限制条件:
- 目标表必须是新建的(即不能导入到已经存在的表)
- 目标表只能有一个列族
- 目标表不能是稀疏的(即每一行数据的结构必须一致)
2. 添加必要的jar包
实测这一步可跳过,不如自己在hive shell上 add jar 。个人感觉hive.aux.jars.path 这个配置比较鸡肋。又不支持直接指定文件夹,发现少了jar包后还得再去编辑文件,需要的jar包一多xml看起来就很恶心。
- 将hive操作所需的jar包上传到hdfs
1
2
3hadoop dfs -put /usr/lib/hive/lib/hbase-VERSION.jar /user/hive/hbase-VERSION.jar
hadoop dfs -put /usr/lib/hive/lib/hive-hbase-handler-VERSION.jar /user/hive/hive-hbase-handler-VERSION.jar - 将其路径添加进 hive-site.xml
1
2
3
4
5
6<property>
<name>hive.aux.jars.path</name>
<value>/user/hive/hbase-VERSION.jar,/user/hive/hive-hbase-handler-VERSION.jar</value>
</property>
3. 确定分区范围
为了最后bulk load的时候可以使用多个reducer加载到多个region,我们需要根据rowkey预先划分好数据的分区范围。这个范围将以文件的形式提供给下一步的中间hive表。这一步的目的就是要得到这个分区文件。
1. 创建分区信息表
分区文件以 org.apache.hadoop.hive.ql.io.HiveNullValueSequenceFileOutputFormat outputformat格式存在于hdfs上。我们可以创建一个分区信息表,指定好该表的存储位置,这样该位置上的文件即为我们要的分区信息文件。
分区信息表的创建如下:
1 | |
2. 插入分区边界
这一步需要插入rowkey的边界。例如,插入数据为 005,则最终生成的hbase的region有两个:下边界005、005上边界。
边界的选择很重要,良好的预分区设计可以减少hbase再平衡的压力,在大数据量下很有用。
因为我们的源表已经存在于hive中了,而目标hbase表的rowkey又是符合字典排序的。所以我们完全可以利用hive的抽样功能先生成hbase的rowkey序列并排好序,再以一定的间隔进行取样,这样就可以得到分布比较合理的边界值了。
抽样的实现参考如下:
1 | |
这里 transactions 是源表,transaction_id 是导入到 hbase 中的 rowkey (实际使用可能需要生成,这里暂用 transaction_id 字段代替)
步骤(1):根据transaction_id字段将数据分到 1万 个桶里,取里面的第一个桶。理论上约等于按 万分之一 进行抽样,抽样后的结果限制最多为 1千万 条。
步骤(2):对步骤(1)的结果按照 rowkey 排序,每 91万 条 取 一条 作为最终结果,最多有 11 条(1000/91<=11)。
步骤(3):将步骤(2)的结果插入到分区信息表
综上,假设源表的数据量在1千亿以上,经过两次抽样后最终最多被划分成了12个region。
注意:桶抽样得到的数量不可靠,在极端情况下步骤(1)抽样的结果可能较少,所以需要自己确定分区信息表的记录行数,后面会用到。
3. 得到分区文件
在hive shell下执行改命令,即可得到分区文件 /tmp/hb_range_key_list
1 | |
4. 生成中间hive表
该表用于生成符合 bulk load 格式要求的hfile文件。最终该表的数据都将移动到hbase中。
1. 准备中间表存储位置
因为中间表的占用的空间一般要比hbase的还大(数据是相同的,但hbase一般会压缩得比较好)
所以中间表的存储位置要特别注意。
如果存储位置不存在,hive会自动创建。如果存储位置已存在,需确保其内容为空。
1 | |
2. 创建中间表
mapred.reduce.tasks=region数量=分区信息表记录数+1
total.order.partitioner.path即为分区文件路径
注意:hfile.family.path=中间表存储路径/列族名
1 | |
3. 导入数据
注意这里使用 cluster by 后加 排序字段(rowkey)
1 | |
5. 完成bulk load
这一步已经和hive没什么关系了,以上面 bulk load 为准。hive的文档有些过时了:
1 | |
三 实验
0 测试环境及数据源准备
1. 环境
实验环境为:CDH6.3.2 parcel安装版本,对应的各个组件版本为:hadoop3.0.0,hbase2.1.0,hive2.1.1
注意,不同方式安装的组件位置不同,jar包位置也不一样
parcels 安装的 默认在 /opt/cloudera/parcels/CDH/lib/组件名
package 安装的 默认在 /usr/lib/组件名
开源hadoop的就随意了
下面的以 parcels 为准
2. 权限相关
请自行解决。
我这里直接把dfs的权限认证给关闭了。生产环境我用的是kerberos,主要需要确保使用的用户对hive、hbase目录有相应的读写权限。
3. 实验用例
参考 hdp的文档: https://docs.cloudera.com/HDPDocuments/HDP1/HDP-1.3.10/bk_user-guide/content/user-guide-hbase-import-1.html
我下载的数据是:
https://dumps.wikimedia.org/other/pagecounts-raw/2008/2008-08/pagecounts-20080801-010000.gz
1 创建源表
1 | |
进入 hive shell 创建表
这里我们创建了 pagecounts 表作为源表
1 | |
我们可以select一下看一下数据的样子
最好再count一下看一下数据量大小,这里可以看到是 3039029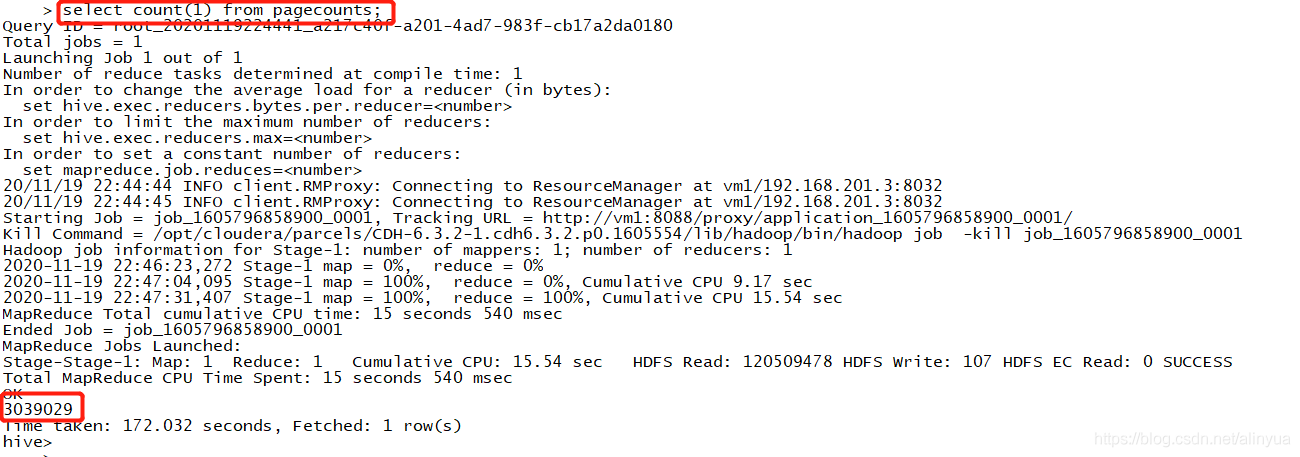
2 创建rowkey视图
创建视图,用于获取自定义的rowkey,以后对源表的操作的转为对此视图的操作
注意必须保证生成rowkey没有重复,不然在最后一步写hfile的时候会报错:Added a key not lexically larger than previous。hbase的api写rowkey重复倒没什么问题,相当于覆盖,但这里是直接写hfile,必须保证rowkey不重复。
实测这里给的rowkey生成方法是会导致重复的。
hql如下:
1 | |

检测重复:
1 | |
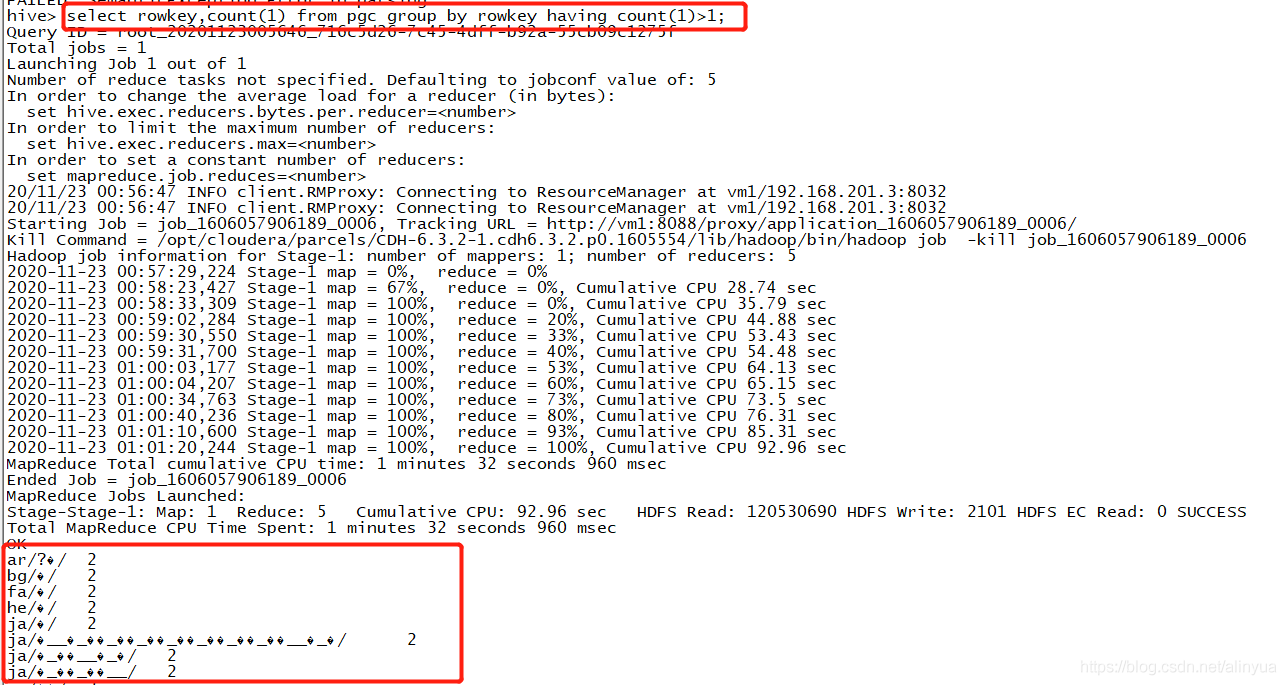
既然如此,我们还是直接创建一个rowkey视图表出来,然后把重复的和源表都删掉吧。
注意hive的distinct是无法识别字段级的重复的,而group by也没办法用在这里,所以我用的是 not in。
1 | |
如果视图pgc没有重复的rowkey就不用那么麻烦再生成pgct表了
3 创建分区信息表
创建的分区信息表名为:hbase_splits
原教程的列名为 partition ,会导致异常,我这里改为了 key。异常信息为:FAILED: ParseException line 1:49 cannot recognize input near ‘partition’ ‘STRING’ ‘)’ in column name or primary key or foreign key
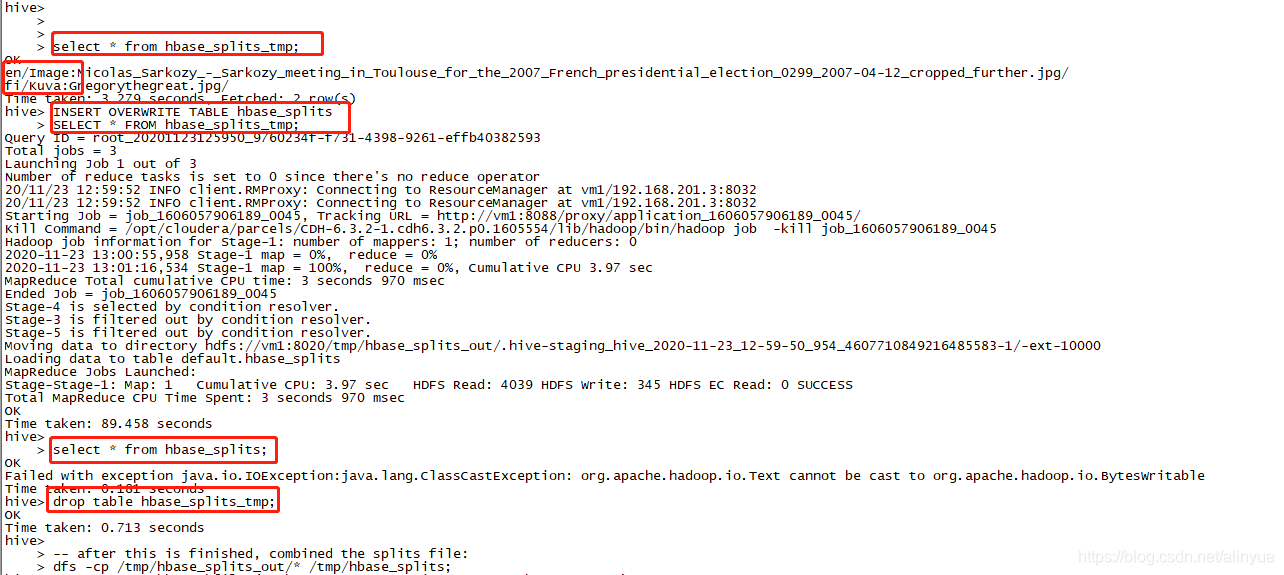
hbase_splits_tmp的作用:
用于获取分区信息的行数
其他的教程都没有写到需要count获取分区信息表的行数,但如果没获取就没办法正确设置下一步的mapred.reduce.tasks。
hbase_splits表由于存储格式和inputformat的关系,存在一些bug,没办法select出内容,甚至连count都不行。所以我这里用了hbase_splits_tmp进行记录,内容先写到hbase_splits_tmp,count完再把hbase_splits_tmp的内容写到hbase_splits上。
1 | |
4 获取分区信息
我们源表的数据在300万条以上(教程里的数据是在400w条左右,这里为了偷懒,就不改了)
这里设计为每1w条抽出一条,得到400条以内的结果,再每100条取1,最终不超过4条rowkey作为边界。
这里为了使用 row_seq 需要添加 hive-contrib 包
这里是对视图进行操作,视图里已经规定了rowkey的设计方法了
最后,要根据存储位置把文件cp成一个文件
1 | |
5 创建hfile表并插入数据
1 创建hfile表
这个表用来生成hfile,这里我们使用的列族为 w
1 | |
2 插入数据
total.order.partitioner.path 用于指定使用的分区排序文件的位置,已经过时,使用 mapreduce.totalorderpartitioner.path 代替。
注意,我这里把hive 的lib下所有带有hbase的包都添加进去了。理论上应该是完整的了,不过实测还是会提示缺少类:.ClassNotFoundException: org.apache.hadoop.hbase.shaded.protobuf.generated.HFileProtos$FileInfoProto。
这个类是在hbase-protocol-shaded.jar包里的,需要到hbase目录里才能找到,也给添加进去,就可以了。
mapred.reduce.tasks数目是前方预估的regions数。
最后一步select出来的数据必须保证无重复的rowkey,实测加distinct 也没用。
1 | |
6 完成bulk load
1. 创建目标hbase表
在hbase shell下执行
1 | |
2. bulkload
bulkload有两种写法,这里推荐使用下面的第二种,不需要设置classpath,如果是使用 hadoop jar需要将 hbase classpath 添加到 hadoop classpath
1 | |
7 总结
不同的版本会有不同的问题。我自己使用的官方开源版本的hive获取分区信息的时候可以直接count,这里用的比较老,似乎就有问题。
另外需要注意可能会各种缺少class,所以建议直接add所有hbase相关的包。
四 参考文章
- hbase官方教程:
http://hbase.apache.org/2.2/book.html#arch.bulk.load - hive 官方教程:
https://cwiki.apache.org/confluence/display/Hive/HBaseBulkLoad - hortonworks教程:
https://docs.cloudera.com/HDPDocuments/HDP1/HDP-1.3.10/bk_user-guide/content/user-guide-hbase-import-1.html - 有赞HBase Bulkload 实践探讨:https://tech.youzan.com/hbase-bulkloadshi-practice/